如今, DeepMind 教会了AI精通围棋的游戏 -并进一步增强了其在国际象棋中的优势-他们将注意力转向了另一种棋盘游戏:外交。与围棋不同,它是七人游戏,它需要竞争和合作的结合,并且每回合玩家都会同时进行移动,因此他们必须推理其他人对他们的推理,依此类推。
DeepMind的计算机科学家Andrea Tacchetti说:“与Go或国际象棋相比,这是一个本质上不同的问题 。” 12月,Tacchetti和合作者在NeurIPS会议 上就其系统 发表了一篇论文,该 论文提高了技术水平,并可能向具有现实外交技能的AI系统指明了道路-与战略或商业合作伙伴进行谈判或只是安排时间您的下一次团队会议。
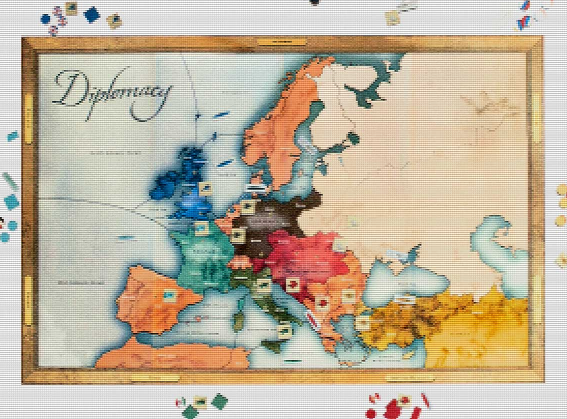
外交 是一种策略游戏,在欧洲地图上划分为75个省。玩家建立并动员军队占领各省,直到有人控制了大部分补给中心。玩家每回合写下自己的举动,然后同时执行。他们可以攻击或防御对方玩家的单位,或者支持对方玩家的进攻和防御,建立联盟。在完整版中,玩家可以协商。DeepMind解决了较简单的No-Press No外交,无需进行明确的沟通。
从历史上看,人工智能使用手工制定的策略来发挥外交作用。在2019年,蒙特利尔研究所 Mila 通过使用深度学习的系统击败了该领域。他们 基于150,000个人类游戏的数据集,训练了一个称为DipNet的神经网络 来模仿人类。DeepMind从DipNet版本开始,然后使用强化学习(一种反复试验)来完善它。
但是,仅通过反复试验来探索可能性的空间会带来问题。他们计算出可以移动20步的游戏将近10 868 种方式-是的,那是10步,后面有868个零。
因此,他们调整了他们的强化学习算法。在训练过程中,他们在每一步中都对对手的可能举动进行采样,计算出在这些情况下平均效果最佳的举动,然后训练自己的球网以偏向于此举。经过培训后,它跳过了采样,仅根据其学习的知识进行工作。
Tacchetti说:“我们论文的信息是:我们可以在这样的环境中进行强化学习。” 他们的一个AI玩家与六个DipNet的AI赢了30%的时间(有14%的机会)。一个DipNet对抗其中的六个,仅赢得了3%的时间。
今年4月,Facebook将在ICLR会议上发表一篇论文,描述 他们在禁止新闻外交方面的工作。他们还建立在类似于DipNet的仿人网络上。但是,他们没有添加强化学习,而是添加了搜索-一种花费额外时间进行提前计划并推断每个玩家下一步可能会做什么的技术。在每个回合中,SearchBot会为每个玩家计算一个平衡,即每个玩家只能通过改变自己的策略而无法提高的策略。
为此,SearchBot通过玩几回合来评估玩家的每种潜在策略(假设每个人都根据网的首选选择后续动作)。策略不是由一个最佳举动组成,而是由50个可能举动组成的一组概率(由网络建议),以避免对对手过于可预测。
在真实游戏中进行这样的探索会减慢SearchBot的速度,但可以使它比DeepMind的系统更胜DipNet。SearchBot还在外交网站上与人类进行了匿名比赛,在玩家中排名前2%。Facebook的计算机科学家,论文的共同作者之一亚当·勒勒(Adam Lerer)说:“这是第一个被证明与人类具有竞争性的机器人 。”
Lerer说:“我认为最重要的一点是搜索常常被低估了。” 他的一位Facebook合作者Noam Brown在超人扑克机器人中实现了搜索 。布朗说,最令人惊讶的发现是他们的方法可以找到平衡点,这在计算上是一项艰巨的任务。
Tacchetti说:“当我看到他们的论文时,我感到非常高兴,因为他们的想法与我们的想法有很大的不同,这意味着我们可以尝试的东西太多了。” Lerer认为将强化学习与搜索结合起来的未来非常适合DeepMind的AlphaGo。
两个团队都发现他们的系统不容易被利用。例如,Facebook邀请了两名顶尖人类玩家对阵SearchBot,每人连续打35场比赛,以探寻弱点。人类只赢得了6%的时间。两组还发现,他们的系统不仅竞争,而且还合作,有时会支持对手。DeepMind团队的Yoram Bachrach说:“他们为了赢得胜利,必须与他人 合作。”
Bachrach,Lerer和Tacchetti表示,这很重要,因为结合了竞争与合作的游戏比诸如Go之类的纯粹竞争性游戏更具现实性。在生活的各个领域中都有各种各样的动机:驾驶交通,谈判合同以及安排Zoom的时间。
我们与可以通过“新闻”进行外交,同时一直使用自然语言进行谈判的人工智能距离有多近?
“对于新闻外交以及其他将合作与竞争结合在一起的环境,您需要进步,”巴赫拉赫说,“就心智理论而言,他们如何与他人就自己的喜好,目标或计划进行沟通。而且,更进一步,您可以查看人类社会拥有的多个代理机构。所有这些工作都非常令人兴奋,但现在还处于初期。”