
哈恩大学和阿利坎特大学的一个研究小组创建了一个应用程序,该应用程序可以自动分析新闻报道并以很高的准确性确定其真实性。
尽管该模型仍处于测试阶段,但它被建议用作过滤每天传给记者和私人读者的大量信息的有用工具。
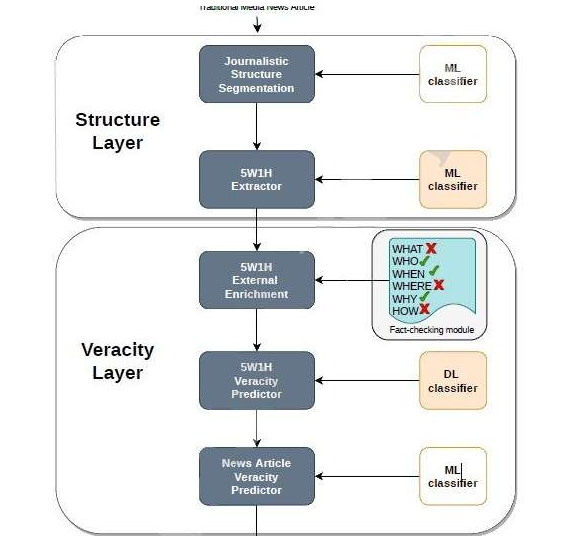
为了识别虚假新闻,科学家开发了基于机器学习的虚假新闻和错误信息可信度推断模型。
这些人工智能技术使系统可以在两个级别上分析新闻,以检测内容是否存在不一致,以及结构是否与具有严格新闻要求的出版物相匹配。
研究人员在“应用程序专家系统”杂志上发表了一篇题为“利用传统数字媒体的话语结构来增强自动伪造新闻检测功能”的文章,其中介绍了网站“伪造新闻”检测器的原型。
该工具旨在为读者提供更大的信心,并为新闻工作者提供新的工具,使他们能够区分不同的信息。
该系统在考虑了传统新闻标准(5W + H规则和倒金字塔)的情况下分析了已发布新闻的结构。
这些参考基于以下事实:严格的新闻报道应包含回答六个基本问题(什么,何时,何地,谁,为什么以及如何)的信息,并应按从最重要到最细的细节的降序排列。
哈恩大学的研究员,该杂志的作者之一米格尔·安格尔·加西亚(MiguelángelGarcía)告诉FundaciónDescubre:“出版物的结构提供了有关其是否具有新闻基础或是否模仿真实新闻报道的线索”文章。
通过对自然语言的分析,专家们开发了一种算法,该算法可检测与该结构不匹配的信息。这些计算基于所谓的机器学习技术,系统在积累越来越多的数据时会“学习”。
此外,该机器能够在几秒钟内处理数千个同时发生的数据,这是人们无法做到的。“因此,新闻记者可以比较并对比消息来源,立即并自动发现标题和新闻正文之间的不正确结构,病毒内容或不一致之处。
最终用户还将获得有关他们阅读的新闻是否符合某些标准的线索。 ”,阿利坎特大学(University of Alicante)的研究人员Estela Saquete补充说,该文章的另一位作者。
通过对自然语言的分析,专家们开发了一种算法,该算法可检测与该结构不匹配的信息。这些计算基于所谓的机器学习技术,系统在积累越来越多的数据时会“学习”。
此外,该机器能够在几秒钟内处理数千个同时发生的数据,这是人们无法做到的。“因此,新闻记者可以比较并对比消息来源,立即并自动发现标题和新闻正文之间的不正确结构,病毒内容或不一致之处。
最终用户还将获得有关他们阅读的新闻是否符合某些标准的线索。 ”,阿利坎特大学(University of Alicante)的研究人员Estela Saquete补充说,该文章的另一位作者。