麻省理工学院的研究人员创建了一个新系统,该系统可以自动清除“脏数据”,包括打字错误,重复项,缺失值,拼写错误以及数据分析师,数据工程师和数据科学家所惧怕的不一致之处。
该系统名为PClean,是概率计算项目的研究人员编写的一系列特定领域概率编程语言中的最新系统,旨在简化和自动化AI应用程序的开发(其他包括通过逆向图形进行3D感知的方法和另一种方法)。用于对时间序列和数据库进行建模)。
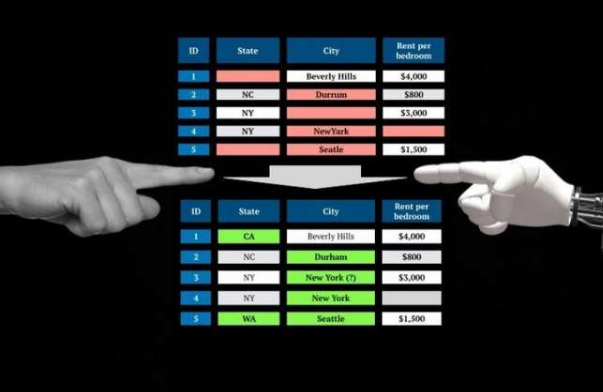
根据Anaconda和图8进行的调查,数据清理可能需要花费数据科学家四分之一的时间。自动化任务具有挑战性,因为不同的数据集需要不同的清理类型,并且经常需要对世界上的物体进行常识性的判断(例如,某人居住在几个城市中,被称为“比佛利山庄”的城市)。PClean为这类判断调用提供了通用的常识模型,可以针对特定的数据库和错误类型进行自定义。
PClean使用基于知识的方法来自动执行数据清理过程:用户对有关数据库的背景知识以及可能出现的各种问题进行编码。例如,在公寓清单数据库中清理州名的问题。如果有人说他们住在比佛利山庄,却把国家专栏留空了怎么办?
尽管在加利福尼亚州有一个著名的比佛利山庄,但在佛罗里达州,密苏里州和得克萨斯州也有一个……而且,巴尔的摩附近有个比佛利山庄。您怎么知道这个人住在哪儿?这就是PClean的表达性脚本语言的用处。
用户可以为PClean提供有关该域以及如何破坏数据的背景知识。PClean通过常识性概率推理结合了这些知识,从而得出了答案。例如,
该论文的主要作者,博士学位的Alex Lew。电气工程与计算机科学系(EECS)的一名学生说,他最激动的是PClean提供了一种从计算机中寻求帮助的方法,就像人们在彼此之间寻求帮助一样。“
当我向朋友寻求帮助时,通常比问计算机要容易得多。这是因为在当今主流的编程语言中,我必须提供逐步的说明,而这不能假定计算机具有任何有关环境的信息。
世界或任务,甚至只是常识性的推理能力。有了人类,我就可以承担所有这些事情。”他说“ PClean是朝着缩小差距迈出的一步。它使我可以告诉计算机我对问题的了解,并使用与我相同的背景知识进行编码。d向帮助我清除数据的人员进行解释。我还可以提供PClean提示,技巧和窍门,这些都是我发现的,可以更快地完成任务。”
合著者是莫妮卡·阿格罗瓦尔(Monica Agrawal),博士。EECS学生;EECS副教授David Sontag;脑与认知科学系首席研究科学家Vikash K. Mansinghka。
哪些创新可以使它起作用?
汉娜·帕苏拉(Hanna Pasula)和加州大学伯克利分校的斯图尔特·拉塞尔(Stuart Russell)实验室的其他人在2003年的一篇论文中曾提出,基于声明式生成知识的概率清洗可能提供比机器学习更高的准确性的想法。“确保数据质量在现实世界中是一个巨大的问题,几乎所有现有解决方案都是临时的,昂贵的且容易出错的,”计算机科学教授Russell说在加州大学伯克利分校。“
PClean是第一个基于生成数据建模的可扩展,精心设计的通用解决方案,它必须是正确的方法。结果不言而喻。” 合著者Agrawal补充说:“现有的数据清理方法在表达方式上受到更多限制,可以更加方便用户使用,但以牺牲有限性为代价。此外,我们发现PClean可以扩展到非常大的,不切实际的数据集现有系统下的运行时。”
PClean建立在概率编程的最新进展的基础上,包括在麻省理工学院的概率计算项目中构建的新AI编程模型,该模型使应用现实的人类知识模型来解释数据变得更加容易。
PClean的维修基于贝叶斯推理,该方法通过将基于先验知识的概率应用于手头数据来权衡含糊数据的替代解释。“做出这类不确定的决定的能力,对于我们要告诉计算机它可能会看到什么样的事情,并使计算机自动使用它来找出可能的正确答案的能力,对于以下方面至关重要。概率编程。” Lew说。
PClean是第一个可以将领域专业知识与常识性推理相结合的贝叶斯数据清理系统,可以自动清理数百万条记录的数据库。PClean通过三项创新达到了这一规模。首先,PClean的脚本语言使用户可以对他们所知道的进行编码。
即使对于复杂的数据库,这也会产生准确的模型。其次,PClean的推理算法基于一次处理记录的方式,采用两阶段方法,以就如何清除记录做出有根据的猜测,然后重新审视其判断错误以纠正错误。这产生了鲁棒,准确的推断结果。第三,PClean提供了一个定制的编译器,可以生成快速的推理代码。与多种竞争方法相比,这使PClean可以在百万记录的数据库上运行,并且速度更快。”
与所有概率程序一样,该工具运行所需的代码行数比其他最新技术选项要少得多:PClean程序仅需要大约50行代码就可以在准确性和运行时间方面胜过基准测试。为了进行比较,一个简单的蛇手机游戏运行的代码行数是原来的两倍,而Minecraft的代码行数超过了100万行。
在刚刚在2021年人工智能与统计学会会议上发表的论文中,作者展示了PClean能够通过使用PClean检测错误并估算220万行Medicare Physician比较医师中的缺失值来缩放包含数百万条记录的数据集的能力。
数据集PClean运行仅七个半小时,发现了8,000多个错误。然后作者(通过在医院网站和LinkedIn网站上的搜索)进行了手工验证,对于96%以上的受访者,PClean提出的修复方案是正确的。
由于PClean基于贝叶斯概率,因此它也可以给出其不确定性的校准估计。“它可以维持多种假设-给您分级的判断,而不仅仅是是/否的答案。这可以建立信任,并在必要时帮助用户超越PClean。
例如,您可以查看PClean不确定的判断,并给出正确的答案然后,它会根据您的反馈更新其余的判断。” Mansinghka说。“我们认为,这种互动过程将人的判断与机器的判断交织在一起,具有很大的潜在价值。
我们认为PClean是一种新型AI系统的早期示例,可以告诉人们更多的了解,并在报告时报告不确定,并以更有用,更像人的方式与人互动。”
DeepMind的高级研究科学家David Pfau在一条推文中指出,PClean可以满足业务需求:“当您考虑到那里的绝大多数业务数据不是狗的图像,而是关系数据库和电子表格中的条目时,它就是想知道像这样的事情还没有深度学习所能取得的成功。”
收益,风险和监管
PClean使将混乱的,不一致的数据库合并到干净的记录中变得更加便宜和容易,而无需以数据为中心的公司目前依赖于对人力和软件系统的大量投资。这具有潜在的社会效益,但也存在风险,其中包括PClean可能会通过加入来自多个公共来源的不完整信息,使其更廉价,更容易地入侵人们的隐私,甚至可能使他们变得匿名。
Mansinghka说:“我们最终需要更强大的数据,AI和隐私法规,以减轻此类危害。” Lew补充说:“与采用机器学习方法进行数据清理相比,PClean可能允许更精细的监管控制。例如,PClean不仅可以告诉我们合并了两个记录是指同一个人,还可以告诉我们为什么这样,我就可以决定是否同意。我什至可以告诉PClean仅考虑合并两个条目的某些原因。” 研究人员说,不幸的是,无论数据集如何清理,隐私问题仍然存在。
曼辛格(Mansinghka)和卢(Lew)很高兴能帮助人们追求对社会有益的应用。希望使用PClean来提高新闻和人道主义应用程序的数据质量的人已经与他们联系,例如反腐败监测和合并提交给州选举委员会的捐助者记录。Agrawal表示,她希望PClean可以腾出数据科学家的时间,“专注于他们关心的问题而不是数据清理。早期对PClean的反馈和热情表明,情况可能如此,我们很高兴听到。”